
В посте мы поговорим о том, как приемы функционального программирования могут облегчить страдания программиста, пишущего пользовательские интерфейсы.
Разница в написании интерфейсов под разные платформы небольшая и скорее количественная, чем качественная. Проблемы общие, подходы общие, без экстремумов и даже серьезных флуктуаций. Поэтому пусть вас не смущает обещание «браузера» в названии: речь пойдет об архитектуре, применимой для любых интерфейсов.
Мы хотим научиться делать сложные интерфейсы: такие, где на экране одновременно присутствуют более одного потока действий. Традиционный подход — потратить много сил и устать — работает, но хочется лучше.
Подход ООП, или более общий «разделяй на компоненты и властвуй», в жизни работает только на банальностях. Компоненты, попав в сложный контекст, начинают зависеть не только от своего состояния, но и от других, выходящих за границы локальной модели, факторов: истории взаимодействия, окружающей обстановки.
Чем сильнее мы хотим придать интерфейсу настоящей человеческой адекватности, тем активнее и запутаннее начинают протягиваться связи всех со всеми. Сложность копится в самом управлении информацией, в огромном массиве нюансов поведения и влияний.
Прямо сейчас мы проблему, конечно, не решим, но витаминки больному прописать попробуем. А именно, обратимся к мудрости предков — функциональному программированию.

Сам по себе термин «ФП», как и любой ультрамодный тренд, намеренно расплывчат, чтобы легче было ловить неадекватов на форумах. Приемы, впрочем, вполне конкретные и дельные.
Чистыми (pure) называются функции, не производящие побочных эффектов: печати, изменения состояния, сетевых запросов. Как правило, чистота фиксируется на уровне соглашений, но бывает и Хаскель. Такие функции безопасно вызывать как угодно, откуда угодно и сколько угодно раз.
Смежным является понятие ссылочной прозрачности (referential transparency) — это функции, не зависящие от глобального состояния, только от собственных аргументов. Результат таких функций можно безопасно кэшировать.
Чистые ссылочно прозрачные функции упрощают чтение кода (наглядно, откуда что пришло и куда ушло) и юнит-тестирование (не нужна установка окружения).
Функциональщики заметили, что бóльшая часть прикладного кода может быть выражена чистыми, ссылочно прозрачными функциями. Императивное программирование остается удобным на уровне библиотечных алгоритмов, грязные функции выносятся за границы ядра и максимально локализуются — так проще следить за эффектами.

ООП приучило нас хранить данные и код вместе, и мало кто задался вопросом: «не грешновато ли?». На самом деле программы всегда в первую очередь про данные: они берут что-то одно (семь) и превращают это в что-то другое (сорок два).
Иметь данные максимально открытыми, доступными, универсальными удобно — к ним можно применять много разных вещей, не только то, что предусмотрел автор программы. Программа может быть даже не всегда запущена, но данные от этого никуда не деваются.

Иммутабельность (immutability) знакома многим по строкам: однажды созданную строку нельзя поменять, но можно создать новую, например, конкатенацией. Со старой при этом ничего не происходит, она все так же доступна (исключение — C/C++, но эти ребята любят, чтобы было трудно).
Такой же подход можно распространить на коллекции: списки, словари, множества, структуры. В иммутабельный список нельзя добавить элемент, но можно создать новый список, в котором на один элемент больше.
Естественно, иммутабельные структуры дороже в использовании, но не летально. Хорошие реализации (persistent data structures) переиспользуют части состояния «предыдущих» объектов так, что накладные расходы получаются небольшими:
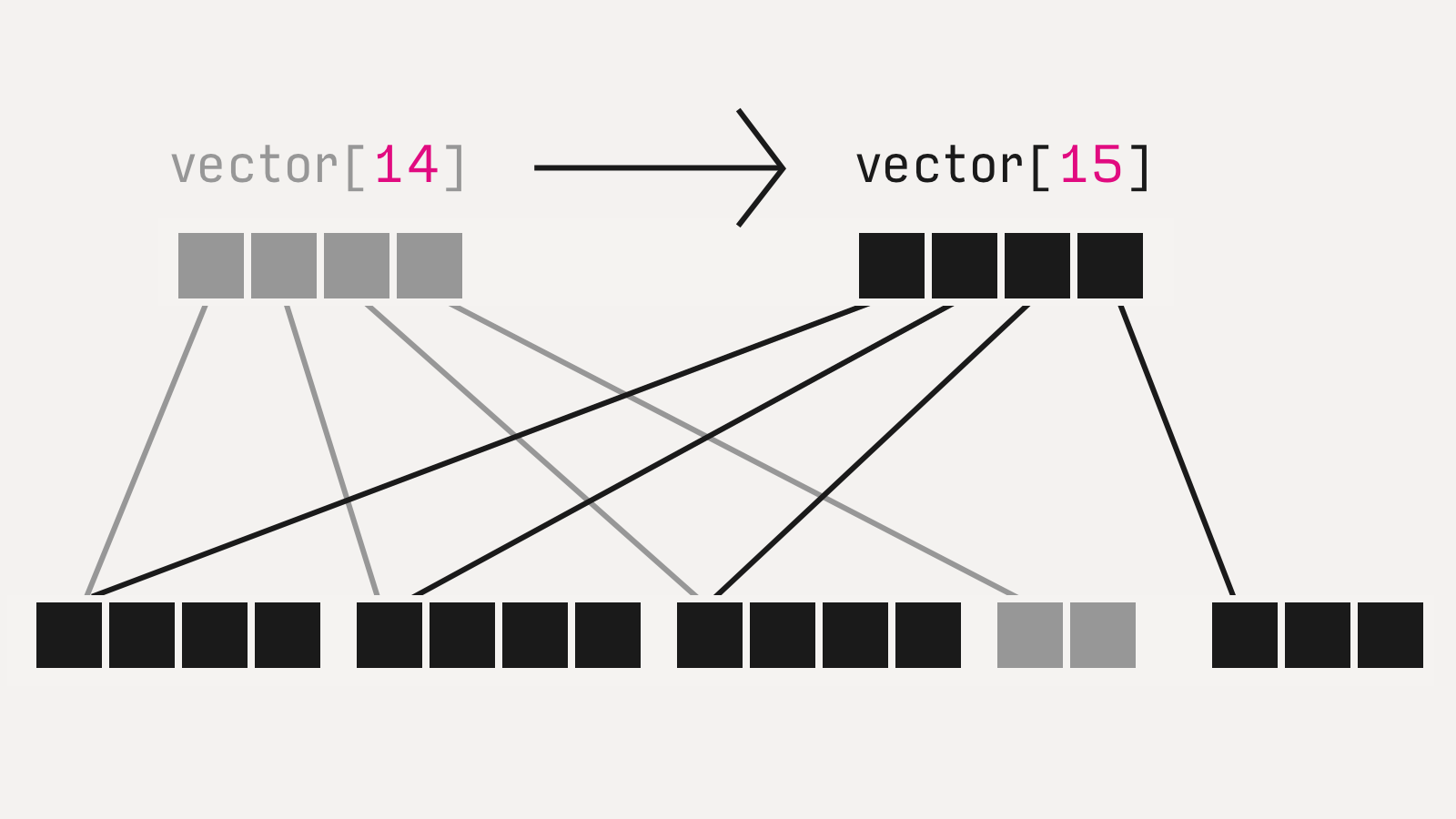
Иммутабельность решает в многопоточной среде, но и для однопоточного кода небесполезна. Она сильно упрощает чтение (легко проследить эволюцию объектов, все изменения явны) и бережет от целого класса ошибок «поменял, запутался, забыл».
Ленивость (lazyness) это способ отложить вычисления до востребования. Вместо ответа функция может вернуть рецепт вычисления ответа, в надежде, что вызывающая сторона сама им распорядится. Используется в основном для оптимизации вычислений.

Давайте посмотрим, как применить все вышеперечисленное туда, куда мы изначально хотели: к веб-интерфейсами.
Традиционный веб-интерфейс это одно большое, сложное, глобальное мутабельное дерево DOM:

Пока все думают, что приложение работает, оно меняет это дерево сразу, бесконтрольно и со всех сторон:

Примерно такие вещи видят функциональные программисты в своих кошмарах: холодный пот, леденящий ужас, крик посреди ночи, element.appendChild().
Предположим, нам удалось сделать DOM иммутабельным и не глобальным. Допустим, DOM-дерево это просто иммутабельное значение. Тогда наше приложение сводится к чистой функции, переводящей один DOM в другой:

Уже неплохо: такое можно юнит-тестировать. Чтобы проверить, что панелька прячется по клику, мы создаем DOM с панелькой, вызываем нашу функцию и смотрим, что она вернула DOM без панельки. Не нужно поднимать браузер, не нужно прокликивать его до нужного исходного состояния, можно вообще в параллель 48 таких тестов гонять.
Теперь примемся за сложность. Если у нас N состояний DOM-дерева, нам надо написать N² функций, переводящих каждое состояние в каждое. Если нужно добавить новое состояние, нужно написать N функций перехода в него и N функций перехода из него. В реальности паутинка будет пореже, но характер зависимости все равно нелинейный:
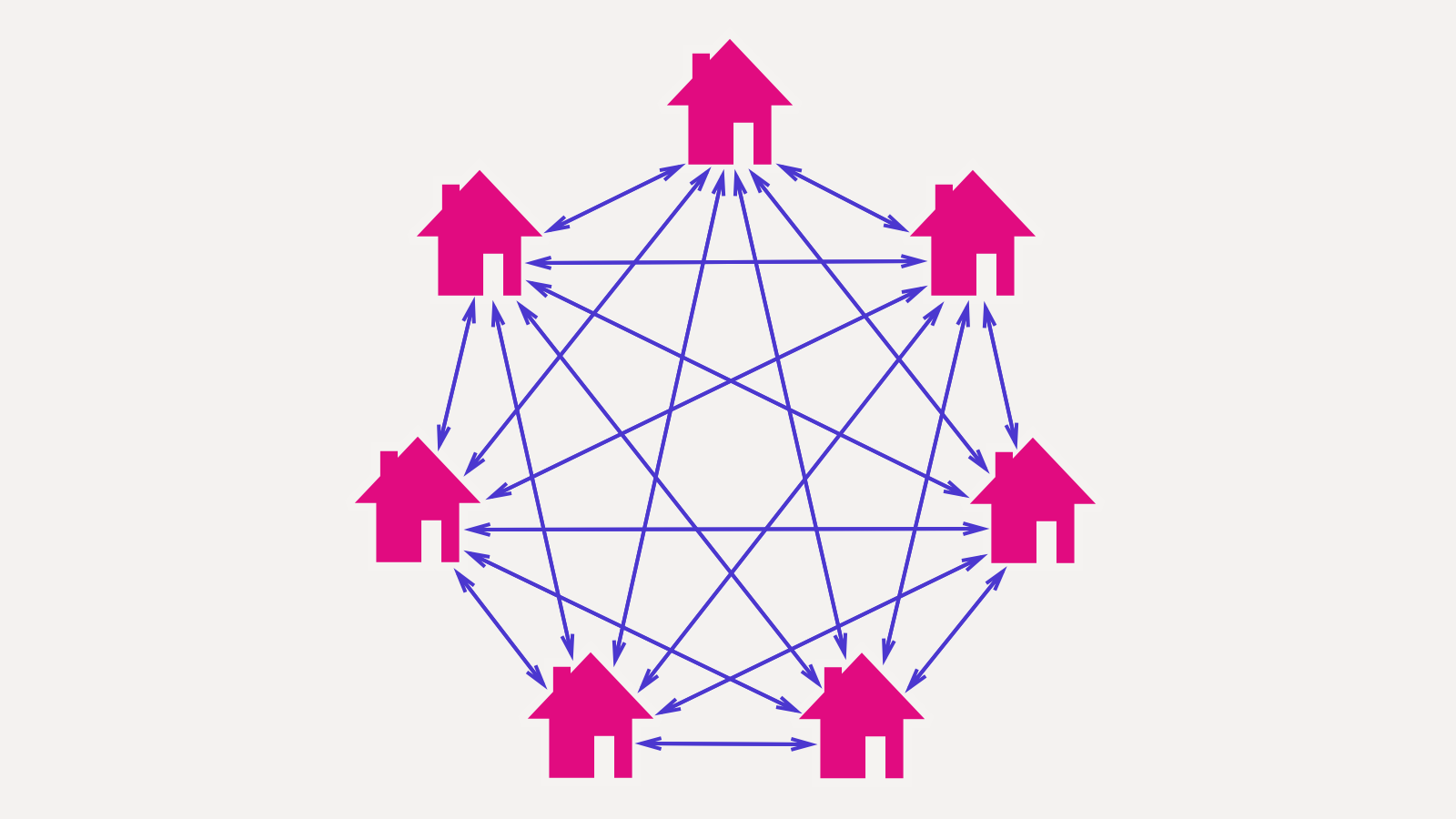
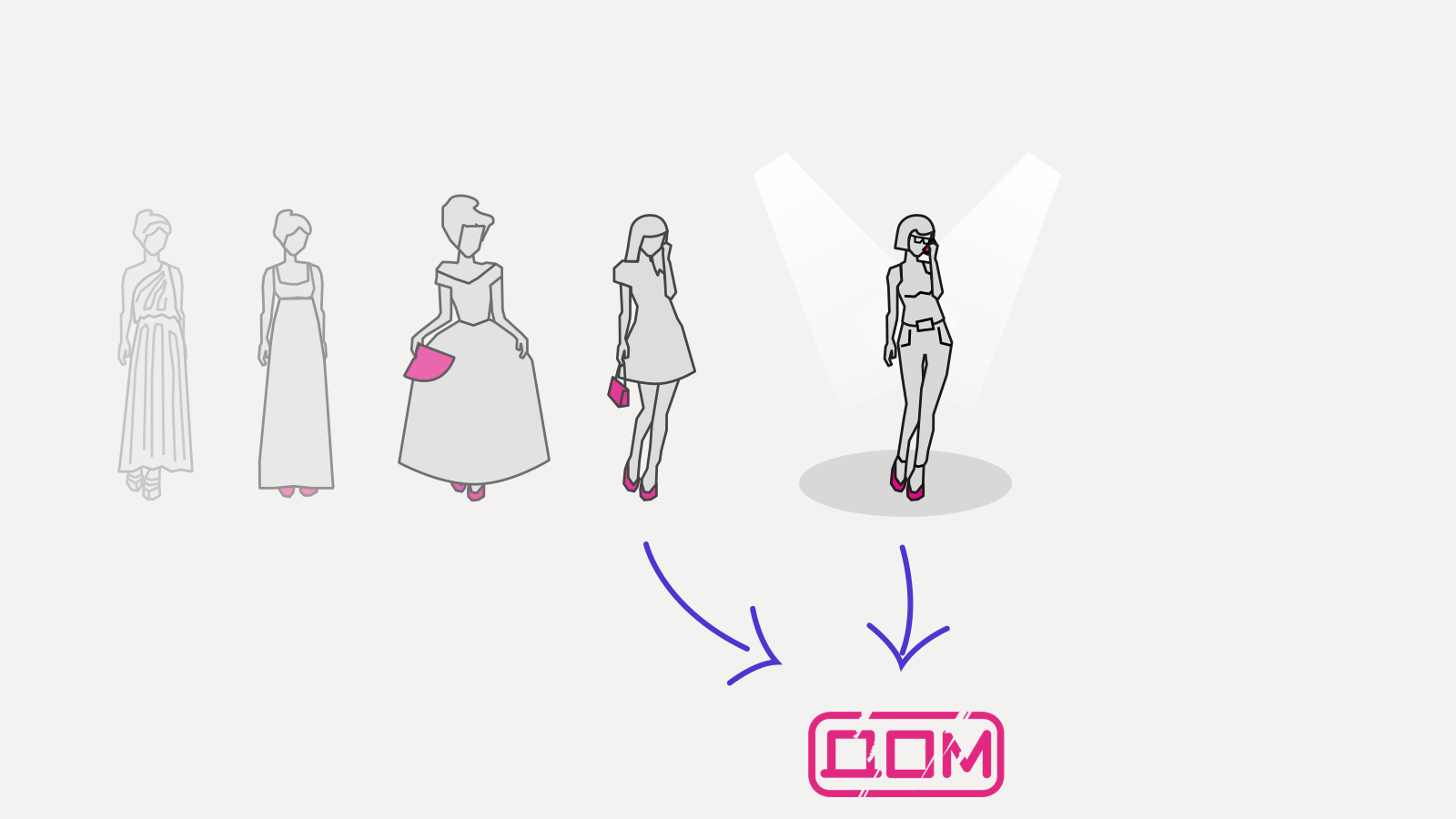
В жизни такое редко бывает, а в программировании вот случилось: нас спасает модель. Мы можем свести наше приложение к функции, переводящей модель в DOM:
Из разных моделей получается разные деревья:
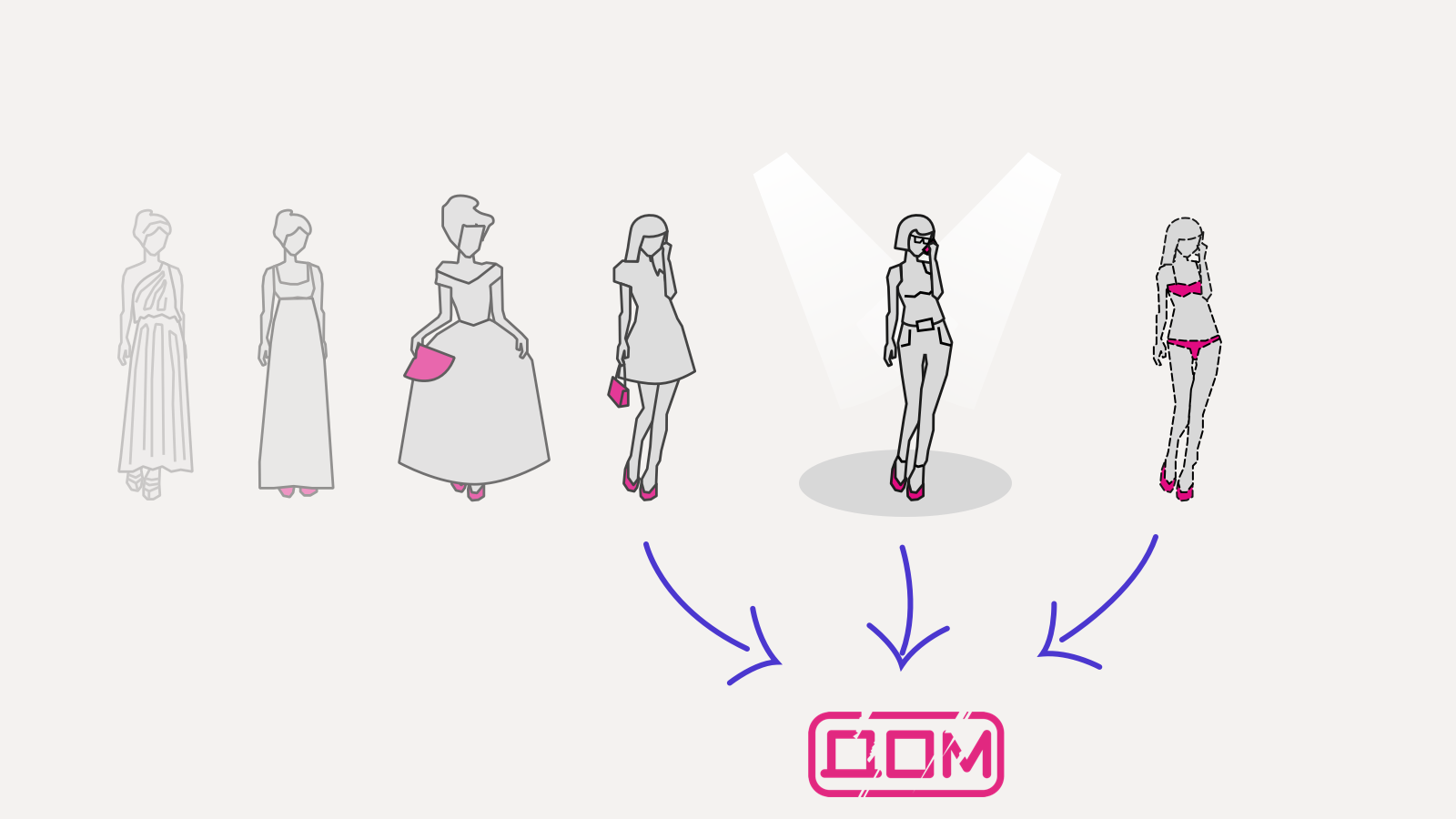
Вся логика реализуется на уровне переходов между моделями. Переходом между DOM-деревьями можно нагрузить библиотеку:
Это придает какую-никакую структуру и существенно снижает количество кода, работающего с DOM: до N вместо N²:
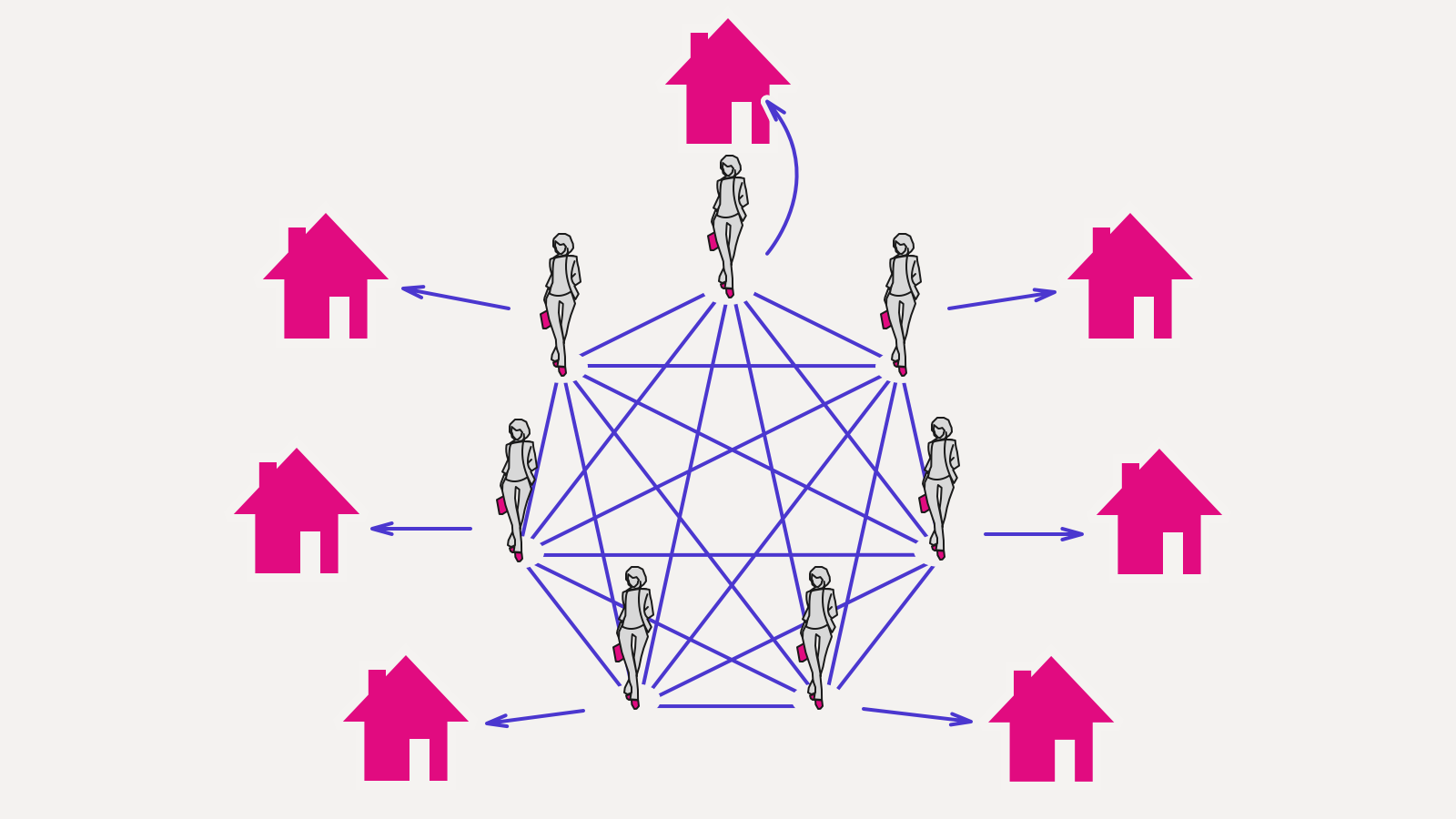
Внимательный читатель заметил, что мы свели проблему переходов между домами к проблеме переходов между моделями. Это действительно так, более того, стрелок на картинке стало больше. Сплошное надувательство.
На практике же получается, что модель устроена гораздо проще и логичнее, чем соответствующее ей DOM-представление. В ней гораздо меньше деталей, переходы тривиальнее, краевые случаи не надо обрабатывать специально. То есть, хотя структурно деталек на картинке больше, на практике это ведет к упрощению кода.
До этого момента я рассказывал о широкоизвестных вещах. Примерно так работает React и другие virtual dom фреймворки. Но даже тут уже цветет функциональное программирование: иммутабельный DOM (на самом деле он разовый, то есть выкидывается сразу после генерации, что делает его эффективно иммутабельным), функция рендеринга чистая (React-у нужна свобода решать, где, когда и сколько раз ее звать), глобальное состояние не используется.
И это мы только начали. Давайте пойдем до конца и объявим иммутабельной и модель тоже:

Теперь логика приложения тоже выражается чистой функцией: переход между состояниями берет старую модель и генерирует на ее основании новую.
Иммутабельная модель дает ключ к ленивому рендерингу. Иммутабельные структуры нельзя незаметно поменять глубоко внутри: надо пойти вглубь, поменять там и все обратно аккуратно перепаковать. Поэтому можно очень быстро определить, грязная модель или чистая: достаточно сравнить ссылки.
Поскольку модель редко меняется целиком, а компоненты приложения зависят от разных частей модели, можно быстро понять, какие куски надо перерисовать, а какие не изменились. Эта оптимизация (shouldComponentUpdate) выключена в React по-умолчанию и включается только вручную под вашу ответственность. Для иммутабельных аргументов ее можно включить сразу везде. Таким образом рендер становится ленивым: вычисляются только те части DOM, которые интересны, все остальное лежит в виде рецептов и не дергается.
Второй приятный бонус иммутабельной модели это хранение истории. Ссылки на старых моделей остаются валидными, и если мы будем хранить их в каком-нибудь списке, можно будет бегать туда-сюда по истории.
Взглянем на архитектуру целиком:
Приложение состоит из одной текущей модели, стека истории моделей и функции рендеринга, переводящей модель в DOM. Поскольку рендеру все равно, откуда пришла модель, легко сделать превью предыдущих состояний истории и отмену по Ctrl+Z.
Более того, поскольку рендеру действительно все равно, можно дополнить архитектуру спекулятивной моделью: все превьюшки, незаконченные операции в процессе, неприменённые настройки можно рендерить, просто вычислив, как выглядела бы модель, если бы. Такая модель нигде не сохраняется, вычисляется на лету и просто разово передается рендеру.
На видео видно стек истории (слева внизу) с превью предыдущих состояний и возможностью откатиться. Фигуры, которые еще находятся в процессе рисования, рисуются через спекулятивную модель:
История наших моделей — это голые данные, соответственно, мы можем строить по ним запросы.
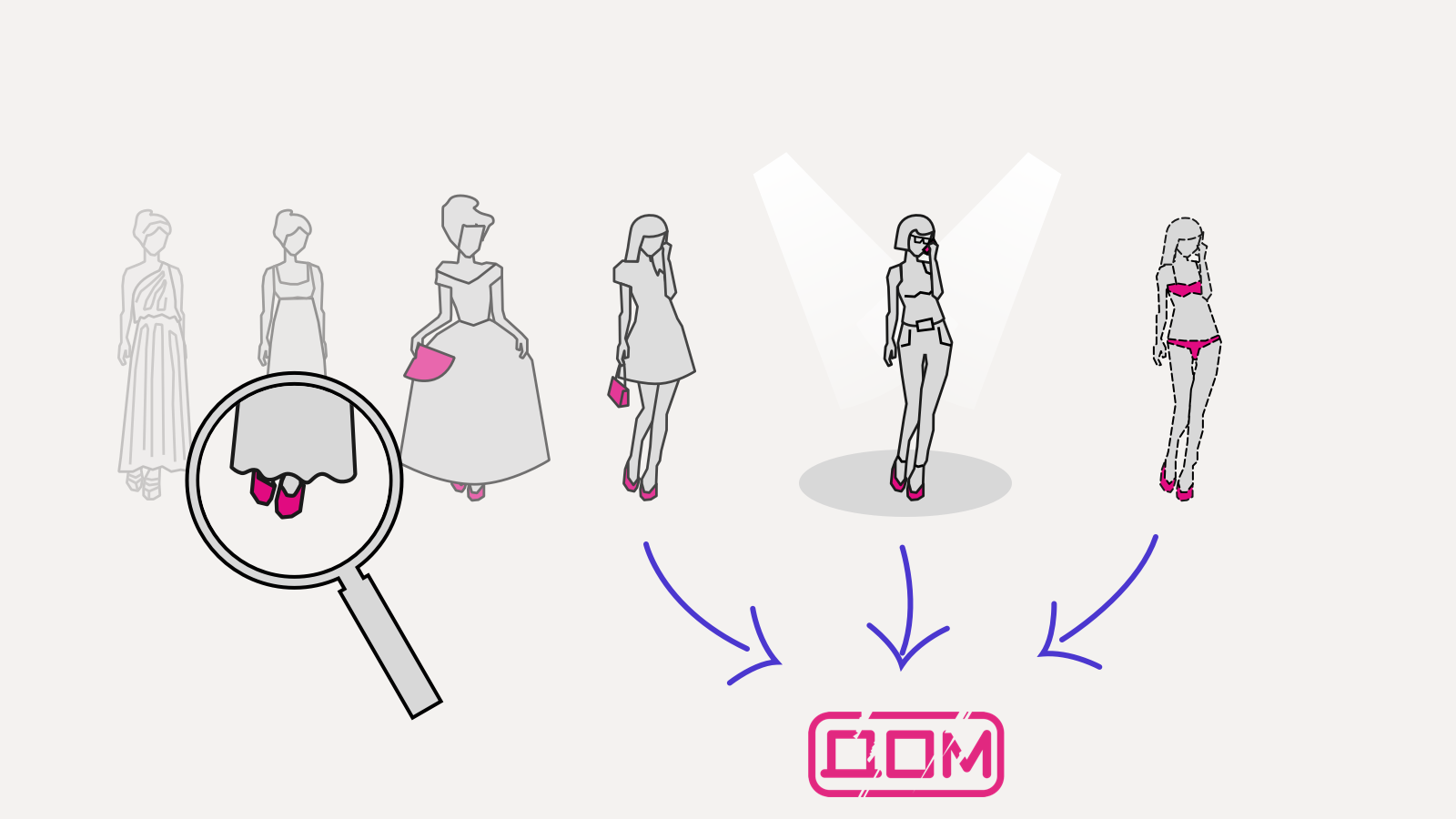
Atomic.io умеет показывать историю конкретного объекта. По сути, они делают срез истории по конкретному объекту и вклеивают старые версии в текущую модель:
Красота модели отдельно еще и в том, как изящно разбивается архитектура на слабосвязанные части. Рендеринг ничего не знает о синхронизации с сервером, сервер ничего не знает о локальном кешировании, и так далее. Модель можно отправить работать на сервере, если, например, откусить от нее рендер. Каждому из них глубоко все равно, откуда и как появилась модель и кто еще на нее смотрит. Это качество, за которое стоит бороться.
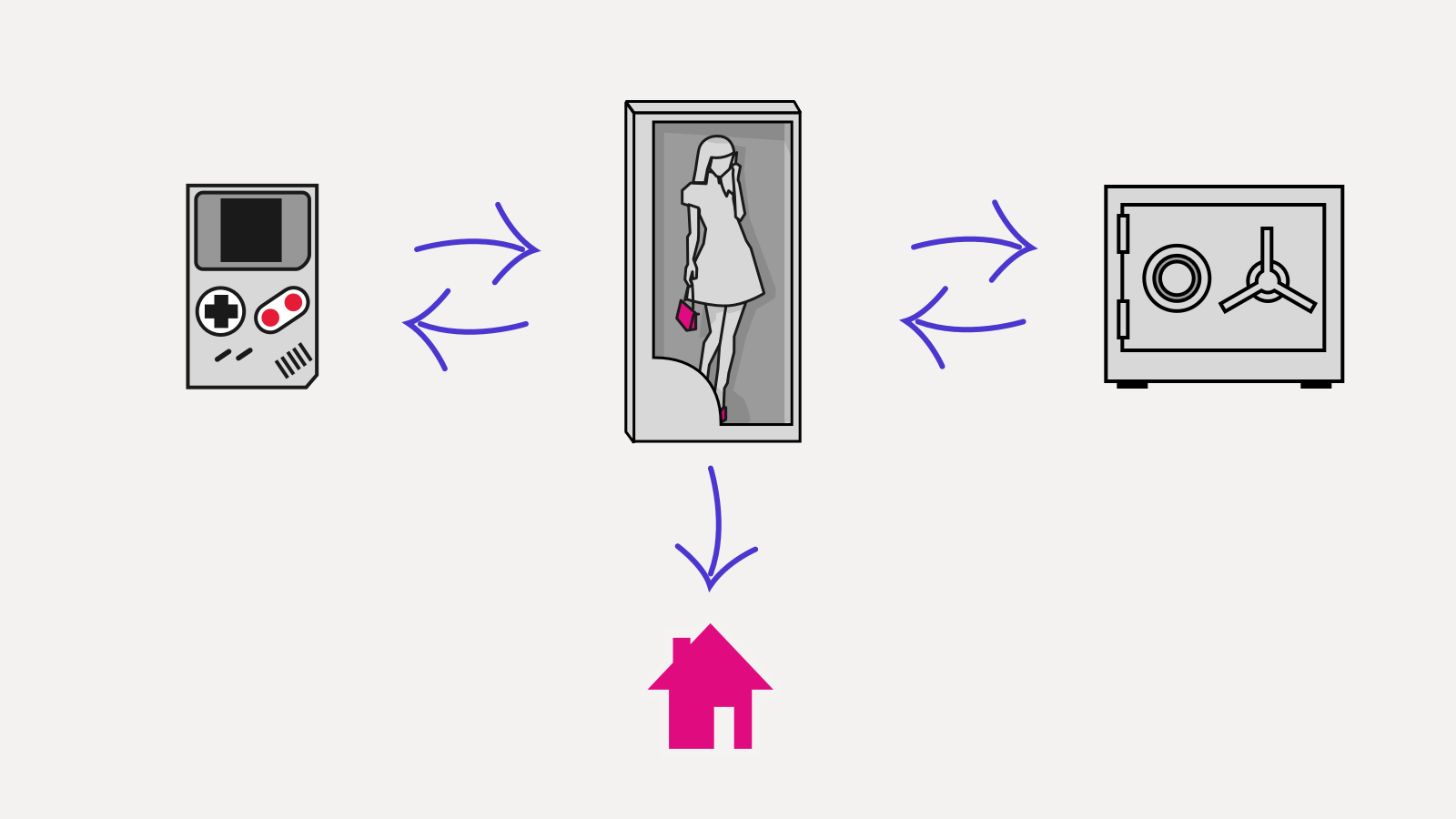
Другой пример, когда иммутабельность может быть полезна: совместная работа с документом. В данной архитектуре используется Event Sourcing: модель это результат свертки (fold) всех произошедших с ней событий (тоже, кстати, функциональный концепт):
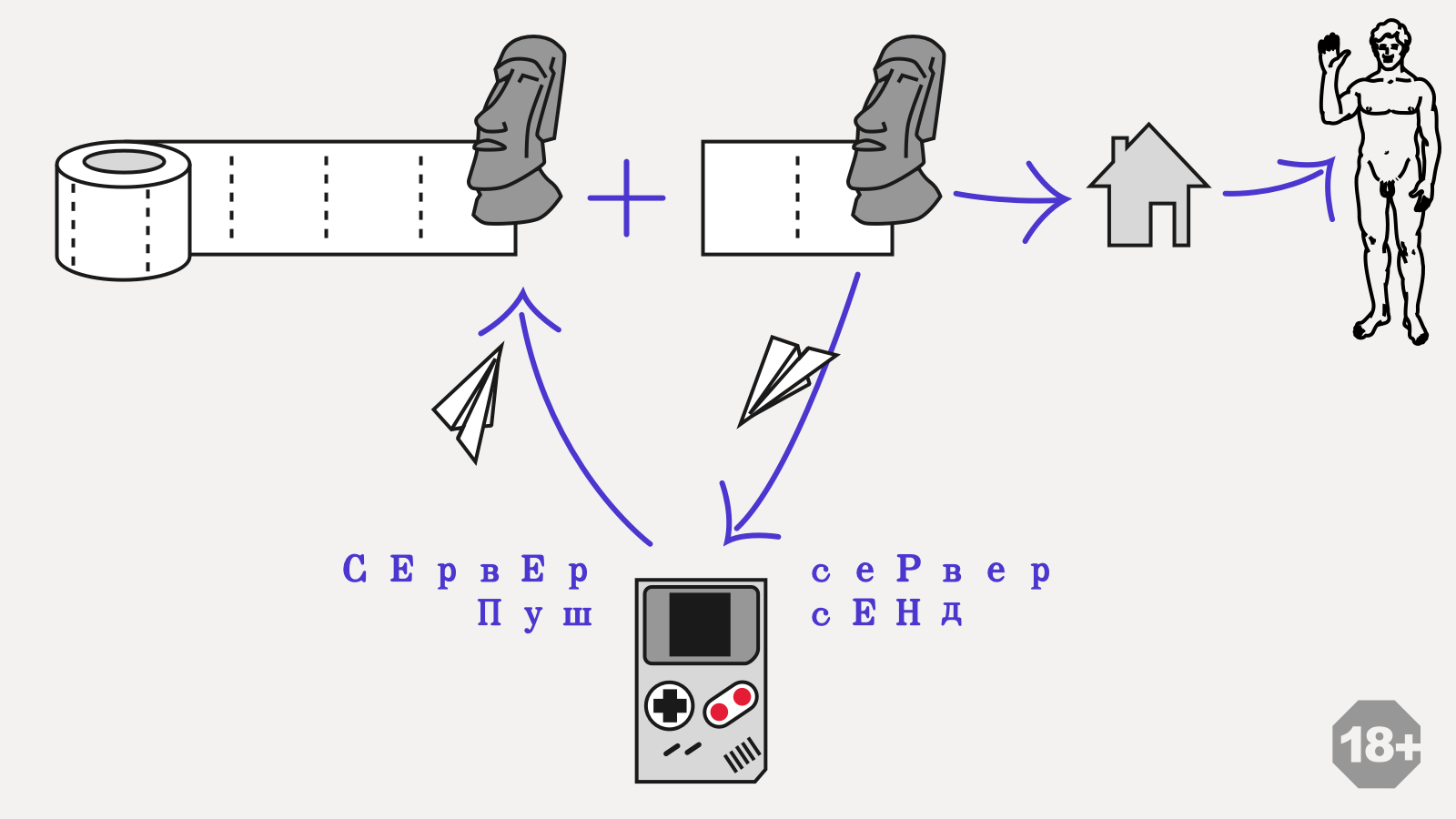
Мы храним два лога событий: локальный и подтвержденный сервером. Все локальные события сначала пишутся в локальный лог. На его основании вычисляется локальная модель и рисуется интерфейс. Это обеспечивает мгновенную обратную связь и работу без интернета.
За кадром, параллельно и независимо, локальный лог пытается синхронизироваться с сервером. Если сервер подтвердил события, локальный лог выкидывается, а подтвержденные события добавляются в подтвержденную часть и применяются к подтвержденной модели. Это обеспечивает идентичность лога на всех клиентах. Уведомление о событиях коллег получается автоматически: сервер просто пушит их сразу в подтвержденный лог.
В этой архитектуре важно иметь возможность хранить предыдущие снэпшоты модели и уметь перевычислять по ним более свежее состояние, ничего при этом не разрушая.
Еще более сумасшедшая штука: отладка с путешествиями во времени:
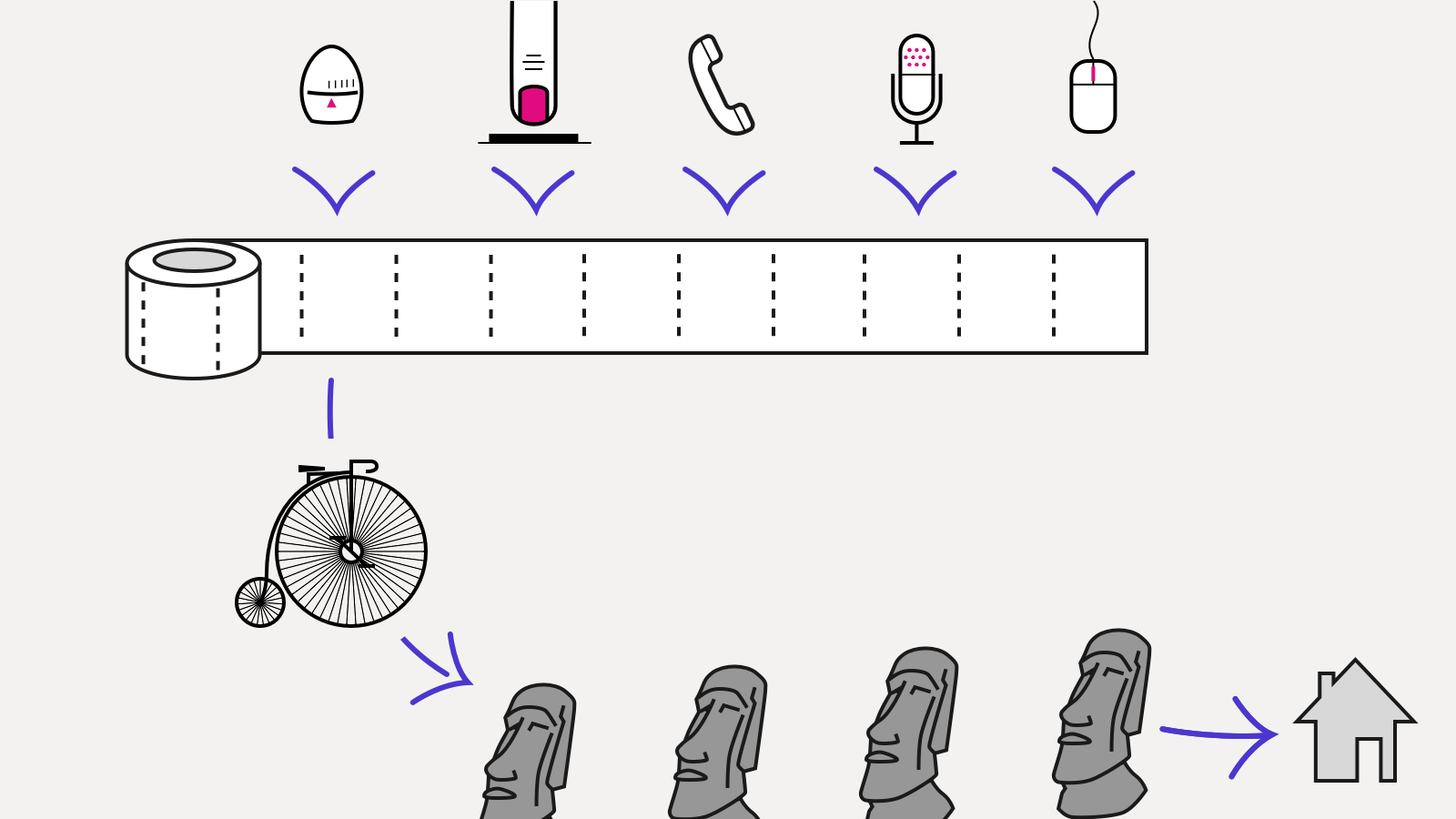
Это тоже своего рода event sourcing, только события здесь записываются на самом раннем, низком уровне — все внешние источники (ввод пользователя, таймеры, сеть) — и только после этого попадают в код приложения.
Такое разделение на (очень сырые) данные и код позволяет сериализовать, переслать и воспроизвести сессию работы с приложением. Что более важно, можно код изменить и посмотреть, как бы выглядела сессия с новым кодом. Пример, собранный на платформе Elm:
Такой подход требует серьезной дисциплины (или технологии, которая ее обеспечит), но и выигрыш почти неслыханный для обычных приложений. Может пригодиться в разработке и техподдержке: получил вместе с багом лог событий, поправил, проверил что баг не повторяется.
Итак, что нужно, чтобы сделать то же самое?

Обязательно понадобятся реализации Virtual DOM (react.js, virtual-dom/mercury) и иммутабельных структур данных (mori.js, immutable.js).
Отдельно хочу упомянуть ClojureScript: это зрелый диалект LISP, компилирующийся в JS. Он функциональный, с иммутабельными структурами по-умолчанию, поэтому делать на нем такие вещи одно удовольствие. Большая часть описанных здесь идей так или иначе зародилась именно в его экосистеме, откуда было растащено эпигонами.

Также я упоминал Elm: это пока экспериментальная разработка, в которой гарантируется строгость и чистота, и многие из описанных вещей получаются автоматически.

Несколько проектов, построенных по описанным архитектурам:
Примеры из совершенно разных областей: от обычного сайта с интерфейсом страницы/ссылки (Prismatic: ClojureScript, Om), через средней интерактивности интерфейс Continous Integration (CircleCI: ClojureScript, Om) до средства прототипирования (Precursor: ClojureScript, Om, DataScript) и веб-графического редактора (Atomic: JS, React, Immutable.js).
Функциональное программирование уже пришло в мейнстрим и хорошо себя зарекомендовало. Виртуальный DOM и иммутабельные структуры, по-видимому, это то, что ждет нас в ближайшем будущем во всех интерфейсах: от банкомата до чайника. Я рекомендую не ждать, пока W3C согласует спецификацию на виртуальный дом для производителей браузеров, а прыгать на этот поезд уже сейчас.
